Part 3 — Using Edge ML in Android: Building a Smart Savings App with Transaction Text Classification
Android Implementation with TensorFlow Lite
This section demonstrates integrating the trained TensorFlow Lite model into an Android application using Kotlin.
Project Setup
Add TensorFlow Lite dependency to your app/build.gradle with Kotlin DSL:
dependencies {
implementation("org.tensorflow:tensorflow-lite:2.13.0")
implementation("org.tensorflow:tensorflow-lite-support:0.4.4")
// For GPU acceleration (optional)
implementation("org.tensorflow:tensorflow-lite-gpu:2.13.0")
}Add Model Assets
- Copy
transaction_classifier.tflitetoapp/src/main/assets/ - Copy
vocabulary.jsontoapp/src/main/assets/
Text Classification Class
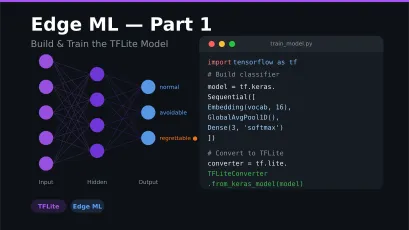
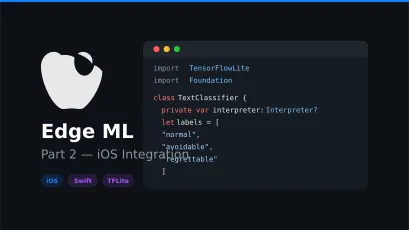
Create the main classification service. Just like in iOS, we load the vocabulary and provide 3 labels — “normal”, “avoidable”, “regrettable”.
package com.dhilip.TransactionClassifier
import android.content.Context
import android.content.res.AssetManager
import org.tensorflow.lite.Interpreter
import org.json.JSONObject
import java.io.FileInputStream
import java.io.IOException
import java.nio.ByteBuffer
import java.nio.ByteOrder
import java.nio.MappedByteBuffer
import java.nio.channels.FileChannel
class TransactionClassifier(private val context: Context) {
private var interpreter: Interpreter? = null
private val labels = arrayOf("normal", "avoidable", "regrettable")
private var vocabulary: Map<String, Int> = emptyMap()
companion object {
private const val MODEL_FILE = "new_transaction_classifier.tflite"
private const val VOCAB_FILE = "vocabulary.json"
private const val MAX_SEQUENCE_LENGTH = 20
}
init {
try {
vocabulary = loadVocabulary()
interpreter = Interpreter(loadModelFile())
println("Model and vocabulary loaded successfully")
} catch (e: Exception) {
println("Error initializing classifier: ${e.message}")
}
}
private fun loadModelFile(): MappedByteBuffer {
val assetManager = context.assets
val fileDescriptor = assetManager.openFd(MODEL_FILE)
val inputStream = FileInputStream(fileDescriptor.fileDescriptor)
val fileChannel = inputStream.channel
val startOffset = fileDescriptor.startOffset
val declaredLength = fileDescriptor.declaredLength
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength)
}
private fun loadVocabulary(): Map<String, Int> {
return try {
val json = context.assets.open(VOCAB_FILE).bufferedReader().use { it.readText() }
val jsonObject = JSONObject(json)
val vocabMap = mutableMapOf<String, Int>()
jsonObject.keys().forEach { key ->
vocabMap[key] = jsonObject.getInt(key)
}
println("Vocabulary loaded with ${vocabMap.size} tokens")
vocabMap
} catch (e: Exception) {
println("Error loading vocabulary: ${e.message}")
emptyMap()
}
}
}Text Preprocessing Implementation
Add preprocessing methods to the class:
private fun preprocessText(text: String): FloatArray {
val lowercaseText = text.lowercase()
// Remove punctuation and clean text (matching TensorFlow behavior)
val cleanedText = lowercaseText.replace(Regex("[^a-z0-9\\s]"), " ")
val tokens = cleanedText.split("\\s+".toRegex()).filter { it.isNotEmpty() }
val tokenIds = mutableListOf<Float>()
for (token in tokens) {
val tokenId = vocabulary[token] ?: 1
tokenIds.add(tokenId.toFloat())
}
// Pad or truncate to exact sequence length
val result = FloatArray(MAX_SEQUENCE_LENGTH)
for (i in 0 until MAX_SEQUENCE_LENGTH) {
result[i] = if (i < tokenIds.size) tokenIds[i] else 0.0f
}
println("Input: '$text'")
println("Tokens: $tokens")
println("Token IDs: ${result.contentToString()}")
return result
}
private fun normalizeTransactionText(text: String): String {
var normalized = text.lowercase()
normalized = normalized.replace(" - chf ", " chf ")
normalized = normalized.replace("-", " ")
normalized = normalized.replace(".", "")
return normalized
}Classification Method
As this is the most important part, I’ll explain in simple terms:
- Prepare text in the same format as the training data.
- Pre-allocate memory for input and output buffer arrays.
- Convert input text to an array of floats and fill the input buffer.
- Run classification.
- Get probabilities for 3 labels and find which category has the highest probability.
fun classify(text: String): String {
val interpreter = this.interpreter ?: return "Error: Model not loaded"
try {
// Normalize and preprocess text
val normalizedText = normalizeTransactionText(text)
val inputArray = preprocessText(normalizedText)
// Prepare input buffer
val inputBuffer = ByteBuffer.allocateDirect(4 * MAX_SEQUENCE_LENGTH)
inputBuffer.order(ByteOrder.nativeOrder())
inputBuffer.rewind()
for (value in inputArray) {
inputBuffer.putFloat(value)
}
// Prepare output buffer
val outputBuffer = ByteBuffer.allocateDirect(4 * 3) // 3 classes
outputBuffer.order(ByteOrder.nativeOrder())
// Run inference
interpreter.run(inputBuffer, outputBuffer)
// Parse output
outputBuffer.rewind()
val probabilities = FloatArray(3)
for (i in 0 until 3) {
probabilities[i] = outputBuffer.getFloat()
}
// Find class with highest probability
val maxIndex = probabilities.indices.maxByOrNull { probabilities[it] } ?: 0
val confidence = probabilities[maxIndex]
println("Probabilities - Normal: ${probabilities[0]}, Avoidable: ${probabilities[1]}, Regrettable: ${probabilities[2]}")
println("Predicted: ${labels[maxIndex]} (confidence: ${"%.2f".format(confidence * 100)}%)")
return labels[maxIndex]
} catch (e: Exception) {
println("Classification error: ${e.message}")
return "Error: ${e.message}"
}
}Usage in Activity/Fragment
Example implementation in your Activity:
private fun testClassification() {
val classifier = TransactionClassifier(this)
val result = classifier.classify("night bar - chf 25.00")
println("Result: -> $result\n")
}When you run this from an Activity, you get the following output:
Probabilities - Normal: 0.001881307, Avoidable: 0.004512803, Regrettable: 0.99360585
Predicted: regrettable (confidence: 99.36%)
Result: -> regrettableThat wraps up our 3-part series. I am already cooking more EdgeML tutorials and will add them in upcoming days 😎